We prototyped three new Mozilla services using the Data Trust model -- here’s what we came up with.
This won’t come as a surprise, but the Covid-19 pandemic has pushed all of us to be more online. Globally, 58% of customer interactions are made through digital services. That’s compared to just 36% in 2019. This is all well and good, but not when only 1% of us actually read the terms and conditions.
This is why IF have been collaborating with Mozilla Foundation and Digital Public to find new solutions in stewarding data. In 2020, we worked together to research, workshop and prototype what some of these solutions might look like for Mozilla.
We explored this challenge by coming up with three different fictional scenarios that we could build services for. The exercise of creating scenarios allowed us to visualise how theory would finally go into practice. This is especially important, because the services we prototyped were built on the emergent idea of Data Trusts.
A Data Trust is a new model for stewarding data: instead of pumping data straight into products and services, users will be able to give permission to a data trust to handle the data instead. The trustees then have a responsibility to steward that data with the user’s best interests in mind. This diagram from Ada Lovelace illustrates the model pretty well.

Data trusts are something which are yet to be put into practice. But this model provided us with a good foundation of data stewarding that goes beyond just being compliant to changing regulations. By creating three fictional scenarios, we were able to prototype use-cases that illustrated the different kinds of services Mozilla could support with a Data Trust set up.
Our three scenarios were:
- Unenforceable regulations: Data protection laws are focussed on user rights, but companies continue to collect data in the same ways
- Extractive data practices: companies use customer data for profit, without asking. Users have the right to use their data for other purposes, but there is no practical way to do so
- Confusing data settings: most services seem to offer ways to control what data is collected and how, but these are confusing and hard to find, leading to user fatigue
These were discussed and challenged through a series of facilitated workshops. Let’s explore these three scenarios and their solutions in more detail:
Scenario one: enforcing regulations through collective action
In this scenario, many jurisdictions have put new data protection laws in place, following public concerns on data privacy. But the laws are yet to produce meaningful change in how companies use and collect data.
What if Mozilla could collectively represent users’ rights to drive product change in line with new laws? How could this work in a data trust model?
Stakeholder needs:
- For your average user of the internet, navigating data rights and collective action is complex; it’s hard for an individual to feel they have any impact.
- Part of Mozilla’s work is to convene activists around campaigns to change products. But often these lack the threat of legal or social force that could compel companies to act.
Proposed Mozilla service: Members give consent to the Trust to represent them in digital rights campaigns. This empowers the Trust to use collective action, which will leverage influence on organisations that use data, policy makers, or regulators.

Scenario two: unlocking different applications of data through a donation platform
In this scenario, companies persistently commodify data, and users have little or no say over this. There are other purposes data can be used for, but no practical way to make this happen.
What if Mozilla could make it easy for people and researchers to unlock data for public good?
Stakeholder needs:
- People may want to contribute their data to causes they care about, but there is no safe way to share the data that organisations hold about them.
- Researchers using data need a significant quantity of data about people to carry out useful investigations, and this is hard to aquire.
Proposed Mozilla service: a data donation platform, built on the data trust model. People share (or donate) whatever data they like with the platform. The trustees then make considered decisions about what the data could be used for, via mass Subject Access Requests. The trustees are merely custodians for the data -- users who donate make clear what they want their data to do, and the trustees are responsible for carrying that through.

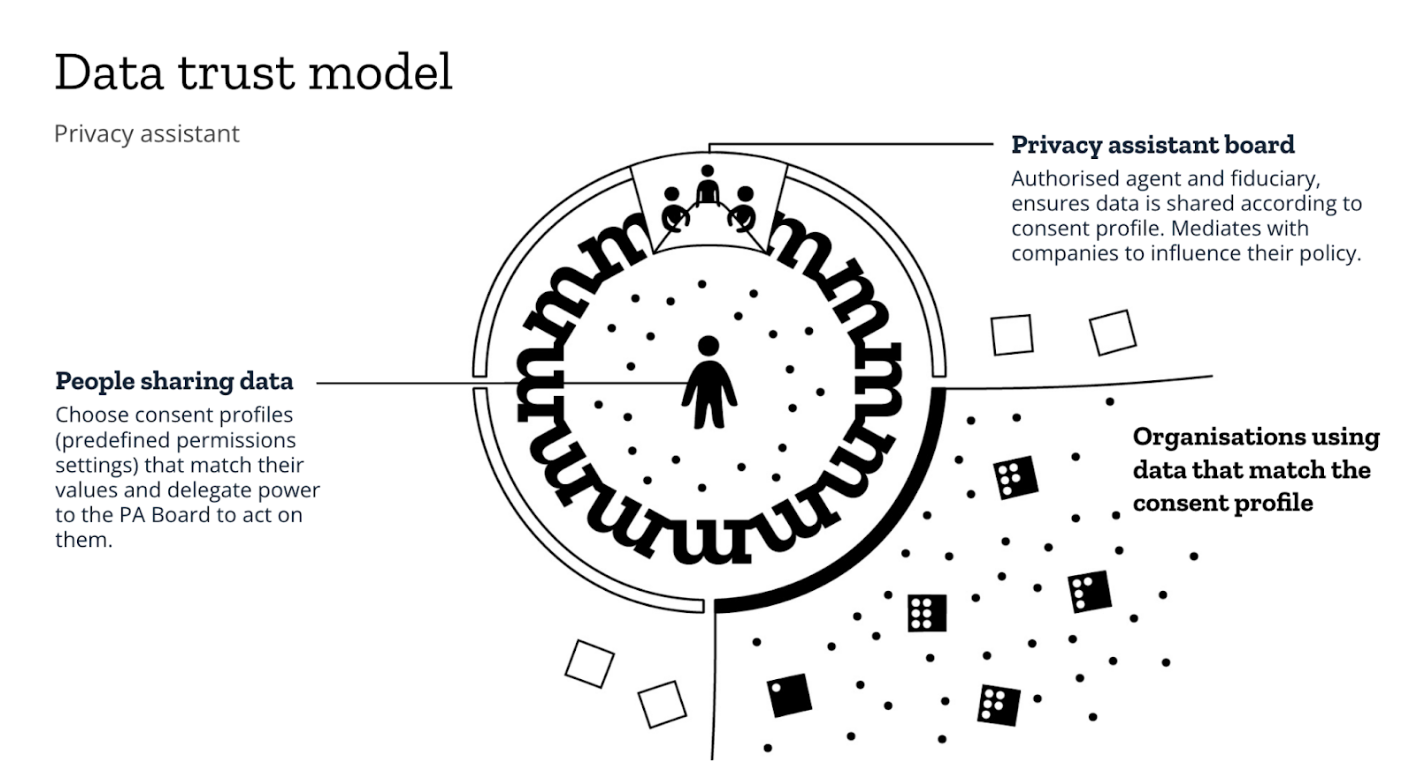
Scenario three: creating consent management via a privacy assistant
In this scenario people are increasingly confused about how to control their data privacy settings. Controls are hard to find, and extremely limited in what they can do.
How can Mozilla help facilitate more straightforward consent management for users?
Stakeholder needs:
- People want peace of mind that companies use data appropriately and inline with their wishes. But the controls provided by companies do not allow people to express their views.
- Organisations should be able to use data with confidence in their users’ approval. Permission controls are not effective, so it’s hard to know when or if users’ provide consent.
- There are impacts of data sharing that are only felt by specific groups, e.g. bias in algorithms or targeted surveillance. Available controls seem to centre the individual, and do not take groups under consideration.
Proposed Mozilla service: a privacy assistant powered by a data trust, that mediates between people and services to make better decisions about data and privacy.
Workshopping these ideas made a couple of things abundantly clear...
Effective data governance should be built around the needs of people: If designed around people and their needs, new data stewardship could have a positive impact for citizens and companies alike: a greater collective understanding of what data can really do, increased participation, and decreased risk for companies storing data.
We need new methodologies to use data responsibly: to get there, we must move beyond theoretical discussions into making and testing. We need to uncover new frameworks, methodologies and ways of working in order to create services which use data responsibly, and finally inspire user trust.
With thanks to the team who collaborated between September - October 2020. From IF: Georgina Bourke, Andrew Eland, Sarah Gold, Laxmi Kerai, David Marques, Nico Meriot. Mozilla Foundation: Mark Surman, Sarah Watson. Digital Public: Sean McDonald.