



Zusammenfassung
TikTok ist, mit nach eigenen Aussagen 1 Milliarde Nutzer*innen im Monat, eine der am schnellsten wachsenden Social-Media-Plattformen der Welt. 11 Millionen davon sind laut TikTok Deutsche. Die Plattform spielte, wie unsere jüngsten Recherchen zeigten, eine zentrale Rolle während des Bundestagswahlkampf 2021. Am 26. September gingen 3 Millionen Erstwähler an die Urnen, und einige Beobachter weisen nun auf TikTok als eine mögliche Erklärung für die Wahlbeteiligung junger Wähler*innen.
Zusätzlich zur qualitativen Untersuchung auf TikTok testeten wir auch quantitative Ansätze bei der Analyse von TikTok. Im Zeitraum Juli bis Oktober 2021 arbeiteten wir uns zusammen mit dem Algorithmic Transparency Institute (ATI) und dem datenjournalistischen Team des Bayerischen Rundfunks (BR) durch 366.062 TikTok-Videos, die wir mithilfe von Junkipedia gesammelt hatten, einem investigativen Tool, das das ATI betreibt. Junkipedia ist eine Technologieplattform, die, wie seine Entwickler*innen sie beschreiben, „die manuelle und automatisierte Erfassung von Daten aus dem gesamten Spektrum digitaler Kommunikationsplattformen einschließlich offener sozialer Medien ermöglicht… angetrieben von einem großen und diversen Netzwerk gesellschaftlich engagierter Mitstreiter*innen”.
In diesem Bericht zeigen wir, wie das Experiment aufgebaut war und was wir auf TikTok während des Bundestagswahlkampfs beobachtet haben. Auf der Grundlage unserer Erfahrungen bei der Untersuchung der Plattform wird aus unserer Sicht klar, warum es besserer und transparenterer Instrumente bei Recherchen auf Plattformen bedarf.
Aktuell bestehen enorme Hürden bei der Durchführung von Recherchen über TikTok. Anders als vergleichbare Dienstleister wie Google, Facebook und Snapchat hat TikTok noch keine Tools wie API-Schnittstellen oder Werbebibliotheken eingerichtet, um Journalist*innen und Wissenschaftler*innen Zugang zu Daten über die Plattform zu geben. Ohne solche Instrumente ist es fast unmöglich für uns, dem TikTok-Algorithmus „ins Getriebe” zu schauen und Auslöser von Missbrauch oder Verletzungen nachzuweisen. Wir fordern TikTok auf, Instrumente und Archive zu entwickeln, die der Zivilgesellschaft Einblick und Kontrolle ermöglichen.

Einleitung
„Jeden, der die letzten zwei Jahre mal auf Tiktok war und sich angesehen hat, worüber junge Leute sprechen, welche Themen und Sorgen sie umtreiben - den dürfte das wirklich wenig überraschen” twitterte die deutsche Journalistin und TikTokerin Victoria Reichelt.
Einen Tag nach der Veröffentlichung der amtlichen Ergebnisse der Bundestagswahl 2021 steckte die deutsche Öffentlichkeit bereits tief in einer Diskussion über den Wahlausgang. Die Wahlbeteiligung der unter 25-Jährigen überraschte viele Wahlbeobachter: Statt bei den beiden ehemaligen Volksparteien CDU/CSU und SPD zu bleiben, entschieden sich die knapp 3 Millionen Erstwähler*innen vor allem für die FDP und Bündnis 90/Die Grünen (beide 23 %).
Auch wenn die Gründe für die Wahlbeteiligung nicht direkt auf TikTok oder eine andere Social-Media-Plattform zurückzuführen sind, deutet der Einfluss von TikTok in Deutschland darauf hin, dass es während des Wahlkampfs durchaus eine entscheidende Rolle gespielt haben kann. Unsere im September 2021 veröffentlichte eigene Studie zur Bundestagswahl hat Bedenken geweckt hinsichtlich der mangelnden Kontrolle von TikTok in Bezug auf die Größe seiner Nutzerbasis, das Nutzerengagement und den Gesamtumsatz.
In diesem Folgebericht fassen wir zusammen, was Mozilla, Journalist*innen und andere Nichtregierungsorganisationen auf TikTok im Vorfeld der Wahl beobachtet haben. Wir erläutern auch den methodologischen Ansatz, mit dem wir durch die von ATI erfassten TikTok-Daten gegangen sind. Und zuletzt beschreiben wir einige der Herausforderungen, mit denen Wissenschaftler*innen konfrontiert sind und die sie daran hindern, großflächige Studien dieser Art durchzuführen, und stellen Empfehlungen für TikTok auf, um sozialwissenschaftliche Forschung auf der Plattform zu ermöglichen.
Wahlkampfanalyse auf TikTok: Schmutz und Desinformation
TikTok wurde, wie Untersuchungen gezeigt haben, von Nutzer*innen im Bundestagswahlkampf zur Beeinflussung der öffentlichen Meinung eingesetzt. Ein Bericht des Institute for Strategic Dialogue (ISD) zeigt, wie nicht gekennzeichnete Wahlwerbung, negative Kampagnen sowie Hassreden und Extremismus auf der Plattform verbreitet wurden. Hierfür kamen u.a. falsche Accounts, TikTok-Ästhetik, minderjährige Influencer und plattformspezifische Memes und Sounds zum Einsatz.
In unserer früheren Studie haben wir mehrere TikTok-Accounts aufgedeckt, die sich als politische Institution bzw. wichtiger deutscher Amtsträger ausgeben, in dem sie das Handle @derbundestag bzw. @frank.walter.steinmeier verwenden. Diese Konten verstoßen eindeutig gegen die Community-Richtlinien von TikTok, die es verbieten, sich als eine andere Person auszugeben oder Benutzer über die Identität oder den Zweck eines Kontos irrezuführen. Obwohl diese beiden Accounts monatelang Tausende von Followern und Likes bekamen, wurden sie erst wenige Wochen vor der Wahl von TikTok gelöscht.
Journalisten des Bayerischen Rundfunks entdeckten darüber hinaus ein virales TikTok-Video zum Thema Wahlen, in dem vom Rap-Song „Gangsta's Paradise“ aus den 1990er Jahren begleitet Falschinformationen über Bündnis 90/Die Grünen verbreitet wurden. Die Melodie des Songs wurde daraufhin von mehr als 40 YouTubern verwandt, um ähnliche Videos zu produzieren, von denen einige mehr als 1,8 Millionen Aufrufe erzielten. Handlung und Setting des Videos sind immer gleich: Es ist Wahlnacht, die Grünen haben gewonnen und stellen neue Regeln für das Leben in Deutschland vor. 6 von 7 Aussagen im Video wurden von unabhängigen Faktenprüfern als falsche Behauptungen entlarvt. Solche Videos dürften unter TikToks Regeln zum Verbot von Falschinformationen fallen, wurden aber von der Plattform nicht entfernt.
Eine Durchführung groß angelegter, quantitativer Forschungen zu TikTok ist nur eingeschränkt möglich. Da die Plattform derzeit weder umfassende Transparenztools noch eine API bereitstellt, müssen Wissenschaftler*innen neue Methoden und technische Mittel entwickeln, um Schadens- oder Missbrauchsmuster zu erkennen. Jüngste Recherchen von Mozilla in den USA erforderten beispielsweise das manuelle Durchsuchen relevanter Hashtags, Accounts und Videos in Kombination mit dem Abfragen einer inoffiziellen API, um Probleme auf der Plattform aufzudecken. Die Wissenschaftler*innen des ISD erstellten im Rahmen ihrer Forschung zu Hassreden und Extremismus auf der Plattform einen Datensatz mit 1.030 TikTok-Videos. Die Videorecherche des WSJ stützte sich auf einen großen Datensatz von TikTok-Videos, die mithilfe von 100 automatisierten Accounts erfasst wurden.
Bessere Instrumente für großflächige Studien auf TikTok sind dringend erforderlich. Trotz ein paar vager Hinweise von TikTok bleibt das Betriebsprinzip der Plattform im Dunklen und externe Wissenschaftler*innen ausgesperrt - außer sie finden Möglichkeiten, die fehlende API zu umgehen.
Neue Ansätze für großflächige Recherche auf TikTok
Unser Bericht über TikTok und die Bundestagswahl stützte sich auf qualitative Beobachtungen und Methoden: die Untersuchung von TikToks Richtlinien, Suche nach Hashtags und Accounts, Analyse von Videos und Labels sowie Interviews mit Interessenvertreter*innen.
Wir haben auch mit quantitativen Ansätzen experimentiert, um TikTok in größerem Maßstab zu untersuchen. Hierzu wurde ein großer Datensatz von über 366.000 deutschsprachigen TikTok-Videos überprüft, der mit dem Untersuchungstool Junkipedia des Algorithmic Transparency Institute methodisch erfasst wurde. ATI ist ein Programm der National Conference on Citizenship (NCoC), einer überparteilichen gemeinnützigen Organisation, die sich für die Stärkung zivilgesellschaftlichen Engagements in den USA einsetzt. Das Ziel von ATI ist die Schaffung größerer Transparenz auf den digitalen Plattformen, die die öffentliche Debatte beeinflussen.
Junkipedia ist eine Technologieplattform, die, wie ihre Betreiber sie beschreiben, „die manuelle und automatisierte Erfassung von Daten aus dem gesamten Spektrum digitaler Kommunikationsplattformen einschließlich offener sozialer Medien ermöglicht“, um Forschung an der Plattform im Interesse des Gemeinwohls zu fördern. Junkipedia wird von Sozialwissenschaftler*innen, Journalist*innen und Anwält*innen eingesetzt, um zu untersuchen, wie Falschinformationen, politische Kommunikation, Hassrede und andere Formen sensibler oder schädlicher Online-Inhalte durch Social-Media-Algorithmen verstärkt werden.
In Zusammenarbeit mit dem Datenjournalismus-Team des Bayerischen Rundfunks (BR) und ATI haben wir im Zeitraum vom 5. Juli bis 4. Oktober 2021 Hunderttausende von Videos im Datensatz kategorisiert, markiert und analysiert. Gemeinsames Ziel von Mozilla, ATI und BR war dabei, (1) eine Methodik zur Untersuchung politischer Kommunikation auf TikTok zu erstellen, und (2) eine technische Infrastruktur aufzubauen, um Daten zu sammeln, die über die For You Page, den Empfehlungsalgorithmus von TikTok, erscheinen.
Die Junkipedia-Plattform funktioniert so: Zunächst gelangen öffentlich zugängliche TikTok-Posts über die automatisierte Sammlung von APIs, über Tiplines eingegangene Nutzer*innenhinweise und synthetische Accounts in das System. Die synthetischen Accounts, die von ATI speziell für die Zwecke dieses Projekts erstellt wurden, sollen das Verhalten von Nutzer*innen aus dem gesamten politischen Spektrum in Deutschland zu emulieren. Als Nächstes sichten, kategorisieren und markieren die Wissenschaftler*innen die TikTok-Beiträge in Junkipedia. Dabei können Listen von Kanälen und Suchanfragen überwacht werden, um nach Inhalten zu suchen, die bestimmten Untersuchungskriterien oder Forschungsfragen entsprechen, und diese Daten dann organisieren, kommentieren, analysieren und exportieren.

Die Perspektive von Forschern zu TikTok-Beiträgen auf der Junkipedia-Plattform.
Das Projekt begann am 5. Juli 2021 mit einer Erhebung von Testdaten. Die groß angelegte Echtdaten-Erhebung wurde dann im August eingeleitet und dauerte bis in die erste Oktoberhälfte. Während des gesamten Projekts wurden 366.062 einzelne TikTok-Videos mit insgesamt 69 synthetischen Accounts erfasst. Neben der TikTok-Untersuchung des WSJ, bei der Daten mit 100 synthetischen Konten gesammelt wurden, ist dies einer der größten TikTok-Datensätze, mit denen Wissenschaftler*innen bisher arbeiten konnten.
ATI sammelte Hunderttausende TikTok-Posts, darunter fast 10.000 Posts, die TikTok selbst als mit Wahlen verbunden markierte. Es wäre quasi unmöglich, diese Menge an Inhalten mit manuellen Methoden zu sammeln und zu identifizieren. Im besten Fall ermöglicht dieser methodische Ansatz es, belastbare Aussagen zu Mustern und Trends zu machen, die sichtbar werden, da die Datenstichprobe repräsentativer ist. Zum Beispiel wäre es schwierig, eine verallgemeinerbare Behauptung aufzustellen wie „X% des Engagements in politischen TikTok-Posts scheinen sich positiv mit Inhalten der Y-Partei zu beschäftigen“, wenn nur anekdotische Daten verwendet werden.
Im folgenden geben wir einen Überblick über die Forschungsmethodik und die Erkenntnisse, die wir aus dem Experiment gezogen haben. Dabei beschreiben wir Datensegmente und synthetische Agenten, wie die Sortierung und Kennzeichnung der Daten verlief, was erste Erkenntnisse waren sowie welche Herausforderungen und Einsichten sich während des gesamten Prozesses ergaben.
Erstellung von Segmenten und synthetischen Nutzern
„Wir haben das Projekt mit dem Wissen ins Leben gerufen, dass es auf TikTok verschiedene Arten von echten menschlichen Usern gibt, und wir wollten bestimmte Eigenschaften dieser User nachahmen“, erklärt Cameron Hickey, Direktor des Algorithmic Transparency Institute.
Zum Beispiel gibt es einige User*innen, die an Make-up-Tutorials interessiert sind, andere an Tanz-Memes und wiederum andere, die sich für Bastelsachen interessieren. Dann gibt es welche, die sich für politische Inhalte interessieren – typischerweise Inhalte, die mit ihrer eigenen Perspektive übereinstimmen. Wir haben verschiedene „Segmente“ geschaffen, um die unterschiedlichsten politischen Standpunkte in Deutschland widerzuspiegeln.
Die Wissenschaftler*innen erstellten also zunächst verschiedene Segmente, die Sichtweisen jeder politischen Partei in Deutschland repräsentieren. Sie erstellten auch Segmente, die breitere politische Standpunkte und Themen repräsentieren sollen, darunter solche mit den Bezeichnungen „Anti-Mainstream", „Klimaschutz", „Politik allgemein" und „unpolitisch", eine Kategorie, die im Experiment quasi als Kontrollgruppe agiert.

Verschiedene Segmente wurden geschaffen, um die deutsche politische Landschaft zu repräsentieren.
Für jedes Segment erstellte ATI mehrere synthetische Accounts, die so programmiert waren, dass sie TikTok entlang der jeweiligen Kriterien nutzen. Diese Accounts sind ausschließlich passiv: sie folgen Accounts, schauen Videos an und schauen sich Videos wiederholt an. Sie liken oder kommentieren also keine Videos aktiv.

Synthetische Konten interagieren mit den codierten Konten nur über passive Aktionen.
Das System besteht aus Client und Server. Der Client läuft auf einer mobilen App und führt verschiedene Aktionen eines/einer User*in auf TikTok aus. Außerdem gibt er dem Server Aufgaben wie „Diesem Konto folgen“, „Dieses Video ansehen“ oder „Deinen Feed 30 Minuten lang scannen“ sowie „Alle Videos von 'X-Konto' erneut ansehen“ oder „Alle Videos erneut ansehen, die den Begriff ,Y' in der Bildunterschrift tragen.“ Der Client fährt damit fort, TikTok zu „benutzen”, zu analysieren, welche Videos er sich ansieht, und entscheidet dann, jedes Video erneut anzusehen oder zu überspringen. Jedes Video, das der Client „sieht”, wird an den Server zurückgesendet und als „Beobachtung“ registriert.

Beiträge werden aus dem FYP-Feed der synthetischen Konten gesammelt.
Beim Sammeln von Daten von TikTok durch ATI traten mehrere Herausforderungen auf, u.a. die Schwierigkeit, Daten aus einer hauptsächlich mobilen App zu sammeln, sowie die Herausforderungen, die sich aus den von TikTok eingerichteten Anti-Scraping-Maßnahmen ergeben. „Das Automatisieren des Verfahrens ist ein ständiges Katz-und-Maus-Spiel mit der Plattform und der Technologie“, sagt Hickey. „TikTok ist sehr gut entwickelt, um das Erstellen synthetischer Konten zu erschweren, und daher bleibt dieser Prozess vollständig manuell.“
Dies kommt nicht unerwartet: Schließlich verbieten die Nutzungsbedingungen von TikTok den Einsatz automatisierter Skripte zur Interaktion mit TikTok, um den Missbrauch der Plattform zu verhindern. TikTok ist eine öffentliche Plattform wie Twitter oder YouTube, daher sind alle von ATI gesammelten Beiträge bereits öffentlich verfügbar und jeder kann sie online sehen. TikTok hat jedoch noch keine Tools wie eine API entwickelt, die es Forschern oder Entwicklern ermöglicht, auf Plattformdaten zuzugreifen, und es gibt daher nur sehr wenige Möglichkeiten für Sozialwissenschaftler*innen, groß angelegte, quantitative Forschungen über die Plattform durchzuführen. Wir haben in unserem früheren Bericht Bedenken hinsichtlich der völligen Intransparenz von TikTok geäußert. Mozilla hat sich bereits häufig dazu geäußert, und wir setzen uns weiterhin dafür ein, die Bedingungen für Forschung im Sinne des Gemeinwohls zu verbessern.
Während der gesamten Erstellung des Forschungsrahmens hat ATI Schritte zur Gewährleistung des Datenschutzes unternommen. Zum einen sammelte das System nur TikTok-Inhalte, die bereits öffentlich verfügbar waren. Personenbezogene Daten wurden nicht erfasst, ebenso wenig wie Kommentare zu Videos. Zweitens werden die Daten nach ihrer Erhebung für genau zwei (2) Jahre gespeichert und danach gelöscht. Und schließlich wird der Code kontinuierlich von ATI überwacht und aktualisiert, damit er der jeweils neuesten Benutzeroberfläche von TikTok entspricht. Weiterführende Informationen zu den Recherche- und Datenschutzpraktiken von Junkipedia sind auf der Website und den Nutzungsbedingungen zu finden.
Daten sortieren und kennzeichnen
Während die Daten in die Junkipedia-Plattform flossen, haben wir zusammen mit BR-Journalist*innen und Wissenschaftler*innen von ATI enorme Mengen von Videos sortiert, um festzustellen, ob sie Relevanz für die Recherche hatten oder nicht. Um ein Gefühl für den Maßstab zu bekommen: Täglich wurde während der Laufzeit des Experiments etwa 3.000 bis 9.000 TikTok-Posts auf der Junkipedia-Plattform gesammelt. Die meisten Beiträge mussten von den Wissenschaftler*innen manuell beschriftet werden.
Die Aufgabe wurde in zwei Schritte unterteilt: Zunächst wurde in einem ersten Screening festgestellt, ob ein Post für unsere Untersuchung „relevant“ oder „nicht relevant“ war. In einem zweiten Screening versahen die Wissenschaftler*innen dann jedes Video mit spezifischen Tags oder Labels für die weitere Analyse. Tags waren u.a. „Anti-Migration“, „Pro-Feminismus“, „Anti-SPD“ und „Falschinformation“. Eine erste Liste von Labels wurde vor Beginn der Datenerfassung erstellt, doch konnten während der Erfassung nach Bedarf neue Labels erstellt werden.
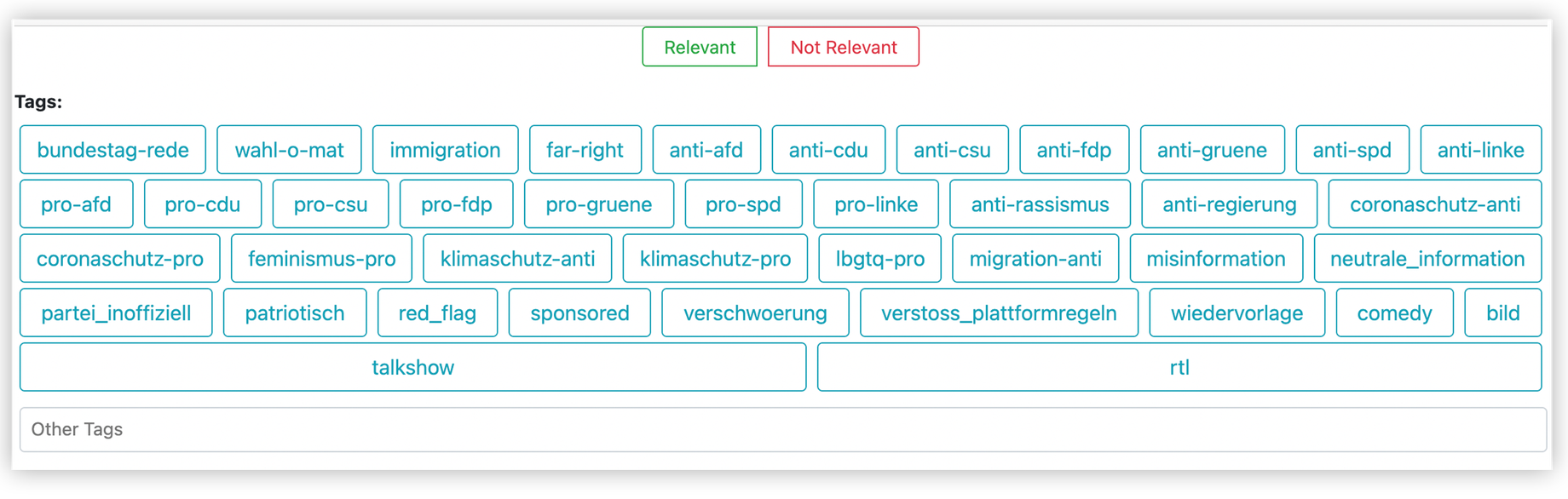
Die Perspektive von Forschern zu Schlagworten einzelner Beiträge auf der Junkipedia-Plattform.
Letztendlich wurden vom 5. Juli bis 4. Oktober insgesamt 366.062 einzelne TikTok-Videos im Junkipedia-Datensatz erfasst. Bisher wurden mehr als 34.000 dieser Videos als relevant bzw. irrelevant gekennzeichnet, davon haben rund 250 Videos zusätzliche Tags erhalten. Für eine umfassende Analyse wäre ein beträchtlicher Einsatz von Arbeit und Zeit erforderlich.
Erste Erkenntnisse
Wir haben die von der Plattform gesammelten Daten als Instrument verwendet, um TikTok-Videos und -Accounts anzuzeigen, die für unsere Forschungsfragen relevant sind. Aufbauend auf den Ergebnissen unseres Berichts vom September 2021 haben wir weitere Accounts identifiziert, die sich als deutsche Politiker*innen ausgeben, und weitere Beweise dafür gesammelt, dass die automatisierten Wahlbanner von TikTok nicht einwandfrei funktionieren.
„Verstärkte” gefälschte Accounts
Unser erster Bericht zeigte, dass Accounts, die sich als deutsche Politiker*innen ausgeben, auf der Plattform florieren. Zusätzlich zu den zwei gefälschten Accounts, die wir im September identifiziert haben, verwendeten wir Junkipedia-Daten, um auf TikTok weitere gefälschte Accounts deutsche Politiker*innen aufzudecken. Die synthetischen Accounts von ATI haben uns beispielsweise auf die Existenz eines Accounts @_angela_dorothea_merkel aufmerksam gemacht, das sich als Bundeskanzlerin Merkel ausgibt. Wir erfuhren erstmals von dem Account, als wir feststellten, dass mehrere der synthetischen Accounts, die ATI programmiert hatte – Bots aus den Segmenten „Anti-Mainstream“, „CDU/CSU“ und „AfD“ – seine Videos auf ihrer For-You-Seite präsentiert bekamen. Sie „sahen” die Videos jeweils am 17. August, 11. September, 14. September und 15. September.
Der Account wurde zu einem bestimmten, uns unbekannten Zeitpunkt nach dem 15. September gelöscht oder entfernt, doch waren seine Videos zu diesem Zeitpunkt von TikTok-Nutzer*innen bereits mehrere Millionen Mal angesehen, wie unser Blick in Junkipedia uns gezeigt hatte. Schwer zu sagen, wie weit die Aussagen des Accounts es schafften und ob seine Videos die deutschen Wähler*innen beeinflussten oder nicht. Die Community-Richtlinien von TikTok verbieten es, sich auf betrügerische Weise als eine andere Person oder Organisation auszugeben, und dennoch blieb der Account im Vorfeld der Wahl monatelang aktiv.
Automatisiertes Kennzeichnen
Ab dem 20. Juli wurden verschiedene TikTok-Videos mit einem Infobanner am unteren Rand versehen, auf dem „Infos über die Bundestagswahl in Deutschland“ stand, mit einem Link zu einer Informationsseite zur Bundestagswahl.
In unseren früheren Recherchen stellten wir fest, dass TikToks automatisierter Ansatz zur Kennzeichnung von Inhalten über die Bundestagswahl nicht wirksam funktioniert, da Videos unsachgemäß gekennzeichnet wurden. Wir kamen zu dem Schluss, dass ein vollständig automatisierter Ansatz, der sich auf Schlüsselwörter stützt, das beabsichtigte Ziel der Kennzeichnung schwächt und dazu sogar noch Bemühungen schwächt, User*innen für diese Problematik zu sensibilisieren und/oder sie an überprüfbare, vertrauenswürdige Informationsquellen heranzuführen.
Auf dieser Recherche aufbauend analysieren wir nun 10.000 Videos in der Junkipedia-Datenbank, die die automatisierten Banner tragen, um festzustellen, welche Faktoren verwendet wurden, um über die Wahllabel zu entscheiden. Wir vermuten, dass das System auf einer groben Liste von Hashtags basiert, die sich auf die Bundestagswahl beziehen. Wir haben zum Beispiel gesehen, dass jeder Beitrag, der das Tag „#merkel“ verwendet, das Label erhielt, aber Beiträge, die das Wort „merkel“ ohne den Hashtag enthielten, nicht. Wenn dies zutrifft, würde das bedeuten, dass, um die automatisierten Banner zu umgehen, man einfach das „#“ aus der Bildunterschrift weglassen müsste.
Herausforderungen und Erkenntnisse
Natürlich ist es nicht leicht, ein großes Forschungsprojekt wie dieses auf die Beine zu stellen. Und obwohl es noch zu früh ist, quantitative Erkenntnisse aus den Daten zu ziehen, können wir dennoch darüber nachdenken, was am Forschungsdesign des Experiments erfolgreich war und was nicht. Auf der Grundlage ihrer Erkenntnisse arbeiten ATI-Wissenschaftler*innen bereits jetzt daran, das System so anzupassen, dass es in größerem Ausmaß angewandt effizienter funktioniert, um so zukünftige Forschungsprojekte und Untersuchungen zu TikTok möglich zu machen.
Unterschiedliche Segmente
Die größte Herausforderung bleibt, dass es praktisch unmöglich ist, Segmente so genau abzustecken, dass sie die jeweiligen politischen Denkrichtungen voneinander abgetrennt widerspiegeln. „Wir waren sehr erfolgreich dabei, den Empfehlungsalgorithmus so zu trainieren, dass er unserem Agenten Videos fütterte, die von Politik und der Wahl handeln, und nicht Influencer-Memes oder Videospielinhalte“, sagt Hickey. „Allerdings scheint es uns zum jetzigen Zeitpunkt nicht besonders gut gelungen zu sein, einen wirklich eigenständigen „CDU“- oder „AfD“-Empfehlungsfeed zu generieren. Dies hat wahrscheinlich mit dem geringen Gesamtvolumen an politischen Posts auf TikTok und der Tatsache zu tun, dass wir dies für sechs verschiedene Parteien mit überlappenden politischen Interessen versucht haben. In einem anderen Umfeld, wie z.B. dem Zweiparteiensystem in den USA, könnte es basierend auf den Erkenntnissen viel effektiver sein.“
Bisher scheinen sich die Videos, die von einzelnen Segmenten auf ihrer For-You-Seite beobachtet wurden, nicht von den Videos zu unterscheiden, die von anderen Segmenten beobachtet wurden. Aber wir sind noch am Anfang des Experiments und im Laufe der Zeit wird sich dies wahrscheinlich ändern, da Agenten mehr Zeit damit verbringen, Videos auf der Plattform anzusehen und ihre Feeds personalisierter werden. „Eine qualitative Analyse ergab keine eindeutigen Feeds für die Segmente; jedoch sind wir derzeit dabei, eine umfassende quantitative Analyse durchzuführen, um herauszufinden, wie individuell unterschiedlich jeder Feed je nach entsprechenden Regeln war“, sagt Hickey.
Nutzerverhalten simulieren
Trotz aller Bemühungen ist es für ATI sehr schwierig, mit automatisierten Methoden reales Nutzerverhalten auf der App zu simulieren. Echte Menschen haben komplexe, unterschiedliche Interessen; sie interessieren sich neben Politik für vieles andere. Zudem entscheiden echte Menschen nicht nur aufgrund der Bildunterschrift, welche Videos sie ansehen möchten. Im Moment können die Agenten keine Entscheidungen auf dem Inhalt des Videos basierend treffen – also auf Grundlage von Musik, Text, Sprache oder Bilder, eben so wie ein echter Mensch entscheiden würde, ein Video anzusehen oder zu überspringen.
Eine weitere Herausforderung besteht darin, dass die synthetischen Agenten noch nicht autonom sind. Derzeit ist der Agent so programmiert, dass er TikTok scannt und einfache Regeln befolgt, wie zum Beispiel „Schauen Sie sich jedes Video erneut an, das die Begriffe „Covid“, „Impfstoff“ oder „Pandemie“ enthält. Der Agent ist auch in der Lage, eine Liste von Videos zu öffnen und anzusehen, einer Liste von Accounts zu folgen und seine For-You-Seite zu scannen und Videos von bestimmten Accounts oder Videos, die bestimmte Begriffe in der Bildunterschrift enthalten, erneut anzusehen. Agenten können derzeit jedoch keine Entscheidungen darüber treffen, was sie basierend auf dem Inhalt des Videos erneut ansehen möchten. Das System muss also weiterentwickelt werden, so dass Agenten solche Verhaltensweisen durchführen können.
Erkennen von Agenten
Während des Experiments stellte sich eine weitere Frage: Könnte das automatisierte System von TikTok zur Erkennung von Bots die Ergebnisse des Experiments beeinflussen? TikToks Transparenzbericht 2020 legt Rechenschaft darüber ab, wie viele nicht-authentische Accounts im Jahr 2020 entfernt wurden. Wir wissen also, dass die Plattform über technische Tools verfügt, um nicht-authentisches Verhalten zu erkennen. Während des gesamten Experiments konnte ATI Aspekte des automatisierten Systems von TikTok zur Identifizierung nicht-authentischer Aktivitäten beobachten oder stieß sogar auf sie, und dennoch arbeiteten die Agenten bisher wie geplant ohne Probleme. Es ist jedoch schwer zu sagen, inwieweit TikTok die Agenten erkannte und Schritte unternimmt, um ihr Verhalten auf der Plattform einzuschränken.
Empfehlungen
Wir haben in diesem Bericht gezeigt, dass Wissenschaftler*innen und Journalist*innen bei der Forschung über TikToks Plattform mit zahlreichen Herausforderungen konfrontiert werden.
TikTok stellt Wissenschaftler*innen, die die Plattform untersuchen möchten, derzeit keine Transparenz-Tools oder APIs zur Verfügung. Ohne solche Tools ist es für Wissenschaftler*innen fast unmöglich, „ins Getriebe“ des TikTok-Algorithmus zu schauen und Missbrauchs- oder Schadensmuster zu erkennen. Wir fordern TikTok daher dringend auf, sinnvolle Transparenzinstrumente und Archive zu entwickeln, um Einblicke durch die Zivilgesellschaft zu ermöglichen.
Insbesondere sollte TikTok Tools veröffentlichen, um Wissenschaftler*innen und Journalist*innen, die sich für das Gemeinwohl einsetzen, in die Lage zu versetzen, den TikTok-Algorithmus zu untersuchen. Das könnte eine öffentliche API sein, die Wissenschaftler*innen abfragen können, ein Tool, das die Funktionsweise des FY-Seiten-Feeds simuliert, oder umfassende Transparenzberichte und Archive. Twitter hat beispielsweise eine öffentlich verfügbare API und davon kürzlich eine Version speziell für akademische Forschung veröffentlicht, die genauere Filteroptionen bietet.
Darüber hinaus sollte TikTok ein öffentlich zugängliches Verzeichnis aller auf der Plattform laufenden Anzeigen, Marken-Content und Werbeaktionen entwickeln, wie es andere Plattformen in unterschiedlichem Maße tun (siehe Facebook Ad Library, Snap Political Ad Library, Google Transparency Report). TikTok sollte bei der Gestaltung dieses Verzeichnisses die Richtlinien von Mozilla befolgen und sicherstellen, dass es Content aus allen auf der Plattform laufenden Anzeigen enthält, einschließlich bezahlter Partnerschaften. Damit würde die Aufsichtsmöglichkeit der User*innen über die Durchsetzung der Richtlinien von TikTok ermöglicht und eine unabhängige Forschung zum Online-Werbe-Ökosystem unterstützt.
Schlussfolgerung
Mit einer stetig wachsenden Userzahl und explosiv steigenden Gewinnzahlen ist TikTok dabei, Sinnbild für das nächste Zeitalter sozialer Medien zu werden. Dennoch legt unsere Recherche einen enormen Mangel an Transparenz auf TikTok offen. Angesichts des sich weiter vergrößernden Rückstands gegenüber anderen Plattformen fordern wir TikTok auf, wirksame Instrumente wie ein API oder ein Werbearchiv zur Steigerung der Transparenz zu entwickeln und damit der Zivilgesellschaft echte Einblicke in die Plattform zu ermöglichen.
Referenzen
Behme, Pia: „Ziel ist der Vertrauensverlust in das demokratische System,” DLF, 24. September 2021, https://www.deutschlandfunk.de/desinformation-im-bundestagswahlkampf-ziel-ist-der.1773.de.html?dram:article_id=503439. Zugriff am 9. Oktober 2021.
Hegemann, Lisa: „Was hängen bleibt. Desinformation im Wahlkampf,” Zeit.de, 29. September 2021, https://www.zeit.de/digital/internet/2021-09/desinformation-wahlkampf-bundestagswahl-2021-annalena-baerbock-gruene/. Zugriff am 9. Oktober 2021.
„Inside TikTok’s Algorithm: A WSJ Video Investigation,” The Wall Street Journal, 21. Juli 2021, https://www.wsj.com/articles/tiktok-algorithm-video-investigation-11626877477. Zugriff am 9. Oktober 2021.
Köver, Chris: „Warum die FDP bei Erstwähler*innen punktete,” Netzpolitik, 29. September 2021, https://netzpolitik.org/2021/bundestagswahl-warum-die-fdp-bei-erstwaehlerinnen-punktete/. Zugriff am 9. Oktober 2021.
Schiffer, Christian: „FDP-Erfolg bei Erstwählern: Die TikTok-Partei,” BR24, 27. September 2021, https://www.br.de/nachrichten/netzwelt/fdp-erfolg-bei-erstwaehlern-die-tiktok-partei,SkD28Sg. Zugriff am 9. Oktober 2021.
Schmid, Mirko: „Desinformationen vor der Bundestagswahl 2021: Baerbock Ziel Nummer eins,” Frankfurter Rundschau, 6. September 2021, https://www.fr.de/politik/bundestagswahl-2021-baerbock-laschet-desinformationen-luegen-manipulation-gruene-cdu-afd-90965040.html. Zugriff am 9. Oktober 2021.
Schöffel, Robert/Khamis, Sammy: „Videos bei TikTok: Falschmeldungen und ihre Verbreitung,” BR24, 16. September 2021, https://www.br.de/nachrichten/netzwelt/videos-bei-tiktok-falschmeldungen-und-ihre-verbreitung,Sj6kb1H. Zugriff am 9. Oktober 2021.
Seeburg, Carina/Wermter, Jonah: „Wahlkampf auf der Blödelplattform,” Süddeutsche Zeitung, 25. September 2021, https://www.sueddeutsche.de/politik/bundestagswahl-tiktok-soziale-medien-fake-news-politik-1.5420761. Zugriff am 9. Oktober 2021.
Sudah, David-Wilp/Levine, David: „Im Visier der Manipulatoren,” Tagesspiegel, 2. September 2021, https://www.tagesspiegel.de/politik/negative-campaigning-im-visier-der-manipulatoren/27575044.html. Zugriff am 9. Oktober 2021.